

The task

A typical photo with YOLO detections. And an example of a camera can be seen at bottom of the photo.
Pipeline v0 (embedder + search space) and v1 (v0 + realgram)
- We crop regions based on YOLO detections.
- Each crop is passed through the embedder to obtain a vector representation.
- Search for the nearest vector in Qdrant, which stores the search space with embeddings and metadata of annotated crops.
- We take the top-1 result by cosine similarity and assign the product class.
In short: for all products from the annotations, we compute an aging coefficient and a coordinate-overlap coefficient, combine them, and add the result to the cosine similarity from the v0 pipeline.
As a result, we obtain a more robust algorithm that incorporates more context and improves the metric up to 92%.
Remaining issues
- The quality is still far from ideal: on difficult crops — where lighting is poor or part of the product is not visible — our predictions are still almost random, relying mainly on the shelf-level annotation context;
- A large number of “flickers”: when, in consecutive images from the same camera, a product in a certain location has not changed, but its prediction changes due to volatility in the top of the search space. This is the main problem we will address in this article.
Object tracking
What object tracking is and why we need it in our task
- visual features of the object;
- its motion dynamics.
With or without visual descriptors?
Solution v2: v1 + tracking
Applying tracking to our task
- increase prediction stability,
- reduce the number of “flickers,”
- potentially improve classification quality.

A column represents a single image from the camera, and a row represents one set of coordinates. On this particular camera, products hardly change over time and look almost identical, so tracking works well. However, things are far from this good on all cameras.
Modified DeepSORT
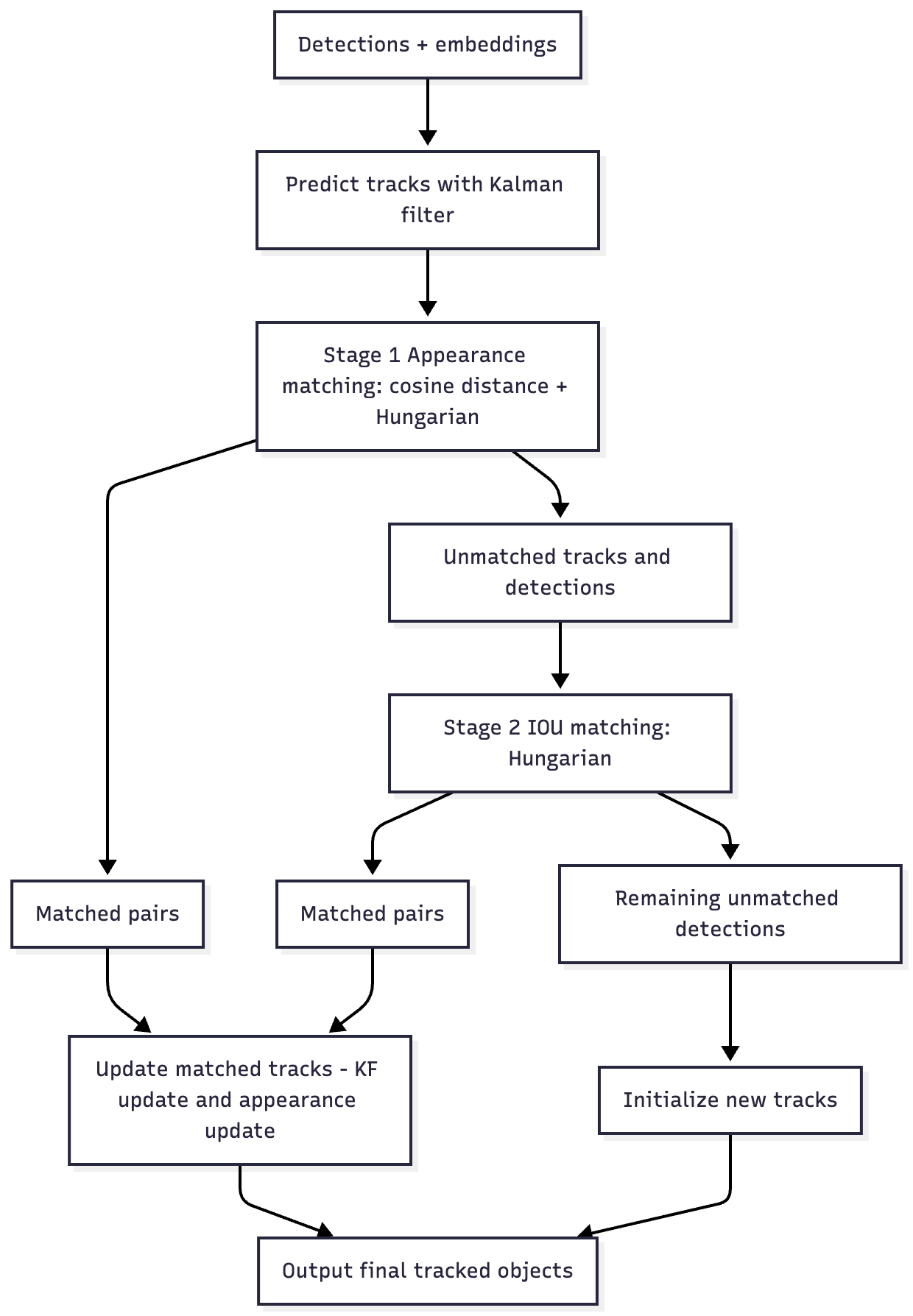
Original DeepSORT: first, matching by embeddings (filtering out unrealistic candidates using a Kalman filter), and then IoU-based matching for detections that were not matched by embeddings.
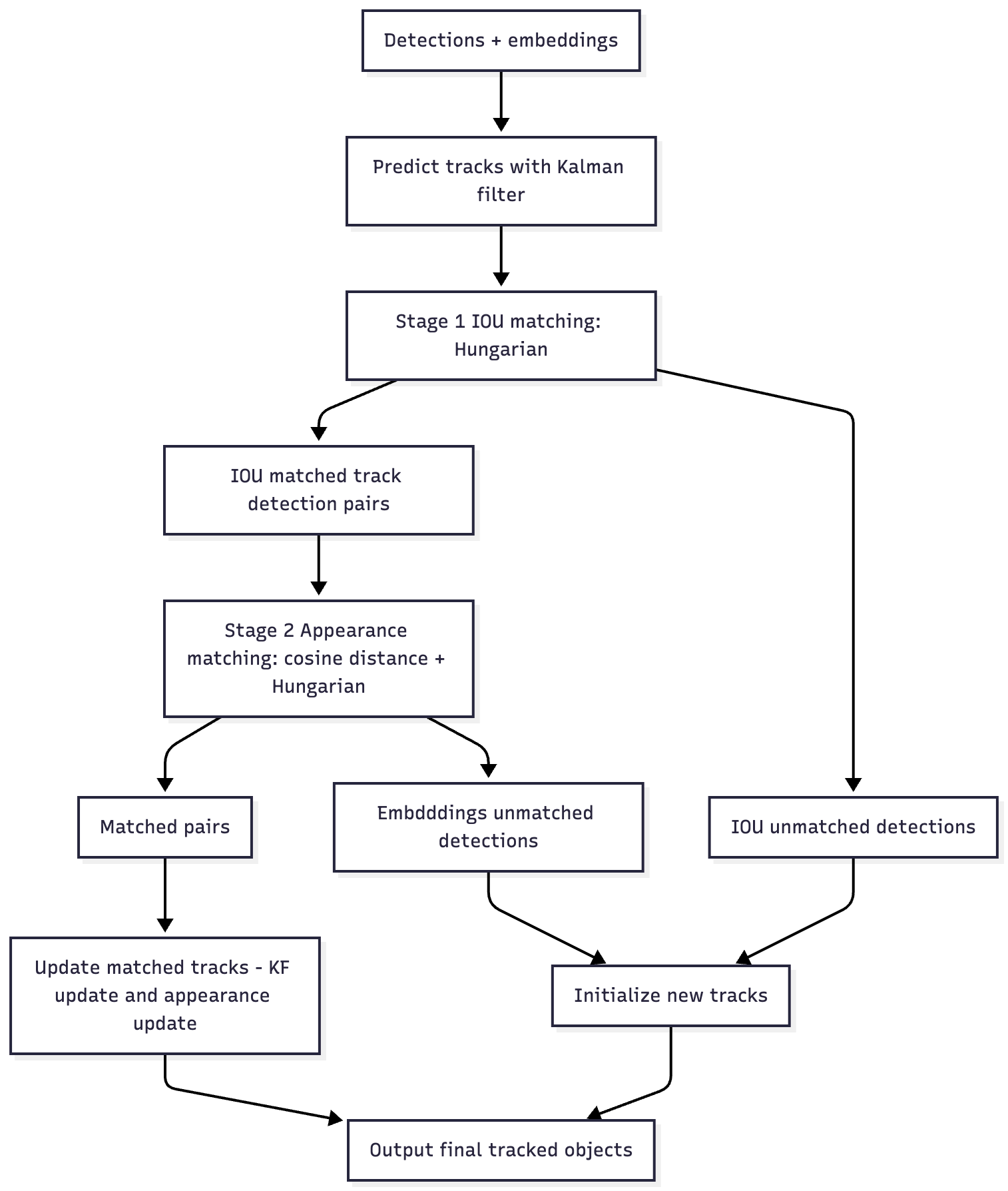
Our version of DeepSORT: first, IoU-based matching, and only for detections that were matched by IoU, embedding-based matching (since products in our case hardly move and visual descriptors are more important for us).
Pipeline v2: adding tracking
About the “most recent unused annotation”
Tracking across frames is a good idea, but if the source for tracking is just the pipeline’s prediction (with, say, 90% accuracy), then in 10% of cases the tracking will “propagate” the error further. To reduce this effect, we use annotations as a more reliable source.
For each frame, we check whether an annotation is available. When a new annotation appears, we run tracking from it once and then continue tracking on intermediate frames. Yes, with each frame the number of tracks created from annotations (we call them “anchor” tracks) decreases, but depending on the thresholds, between 20% and 50% of “anchor” tracks are preserved between annotations.
- If the tracking score (IoU between boxes × cosine similarity between embeddings) is higher than the intermediate prediction score minus a constant (a hyperparameter that defines the level of trust in tracking), we take the prediction from the previous frame.
- Otherwise, we take the intermediate prediction and initialize a track with it.
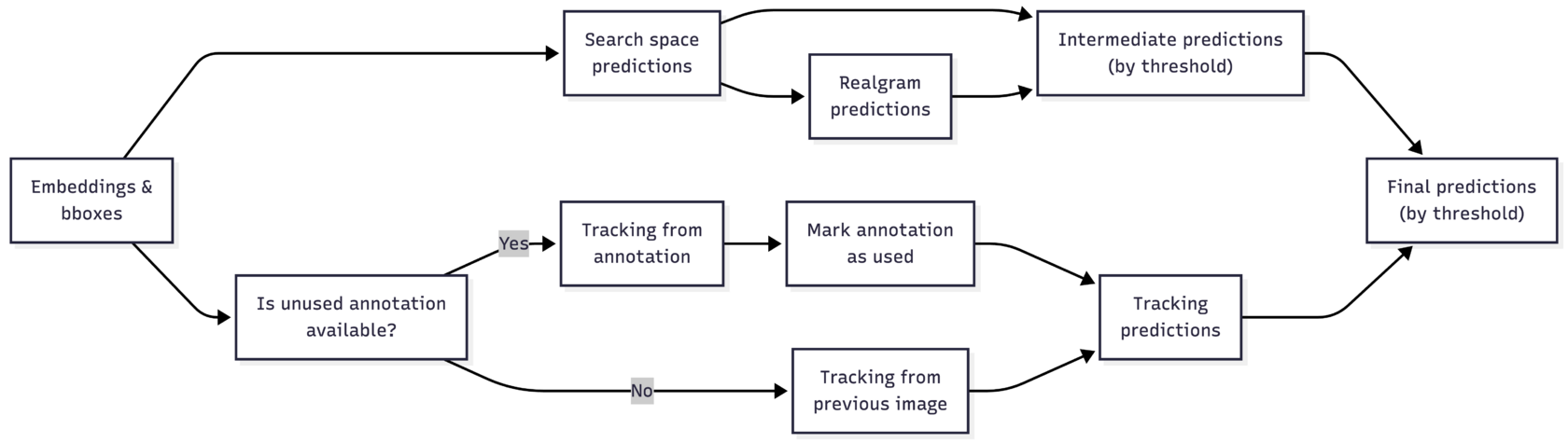
The v2 pipeline looks roughly as follows: we obtain intermediate predictions from the search space and realgram; obtain predictions from tracking; and then select between them based on a score with a threshold.
Nevertheless, the result is there: the metric (its calculation method was described in the previous article) increased from 92% to 94%, and the number of “flickers” decreased roughly by half.
As for the “flicker” metric, at that time we had not yet introduced a separate formal metric, so the estimate of their reduction is qualitative in nature. However, the effect is easy to explain: after adding tracking, the prediction for the current frame is inherited from the previous one much more often, whereas previously neighboring frames were processed independently.
As a result, predictions across adjacent frames began to coincide significantly more frequently, which visually reduces the number of “flickers.”
Results
- Growth in the number of hyperparameters. Realgram had around 10 hyperparameters, and tracking added about 5 more. Even Optuna stopped handling the search effectively, and the risk of overfitting increased, since parameter tuning is performed each time on a limited dataset.
- False positives in tracking. Even with a high tracking score, tracking can “propagate” incorrect predictions. For example, at the same coordinates, one product may be replaced by another flavor or variant that is visually almost indistinguishable. In such cases, the tracker easily picks up the wrong class.
- Increased complexity of candidate selection. With the addition of tracking, we further complicated the selection problem: now we have many candidates from the top search space, realgram, and tracking. There may be one candidate, or there may be twenty. How should we choose among them?

